本ページでは、Python の機械学習ライブラリの scikit-learn を用いて線形回帰モデルを作成し、単回帰分析と重回帰分析を行う手順を紹介します。
線形回帰とは
線形回帰モデル (Linear Regression) とは、以下のような回帰式を用いて、説明変数の値から目的変数の値を予測するモデルです。
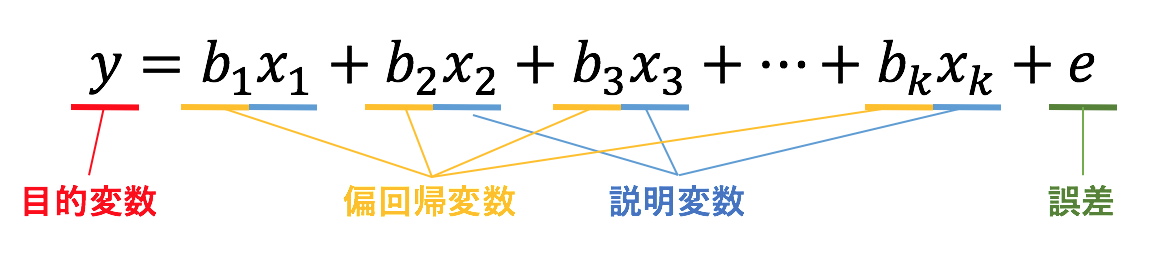
特に、説明変数が 1 つだけの場合「単回帰分析」と呼ばれ、説明変数が 2 変数以上で構成される場合「重回帰分析」と呼ばれます。
scikit-learn を用いた線形回帰
scikit-learn には、線形回帰による予測を行うクラスとして、sklearn.linear_model.LinearRegression が用意されています。
sklearn.linear_model.LinearRegression クラスの使い方
sklearn.linear_model.LinearRegression(fit_intercept=True, normalize=False,
copy_X=True, n_jobs=1)
sklearn.linear_model.LinearRegression クラスの引数
実行時に、以下のパラメータを制御できます。
| fit_intercept | False に設定すると切片を求める計算を含めない。目的変数が原点を必ず通る性質のデータを扱うときに利用。 (デフォルト値: True) |
|---|---|
| normalize | True に設定すると、説明変数を事前に正規化します。 (デフォルト値: False) |
| copy_X | メモリ内でデータを複製してから実行するかどうか。 (デフォルト値: True) |
| n_jobs | 計算に使うジョブの数。-1 に設定すると、すべての CPU を使って計算します。 (デフォルト値: 1) |
sklearn.linear_model.LinearRegression クラスのアトリビュート
以下のパラメータを参照して分析結果の数値を確認できます。
| coef_ | 偏回帰係数 |
|---|---|
| intercept_ | 切片 |
sklearn.linear_model.LinearRegression クラスのメソッド
以下のメソッドを用いて処理を行います。
| fit(X, y[, sample_weight]) | 線形回帰モデルのあてはめを実行 |
|---|---|
| get_params([deep]) | 推定に用いたパラメータを取得 |
| predict(X) | 作成したモデルを利用して予測を実行 |
| score(X, y[, sample_weight]) | 決定係数 R2を出力 |
| set_params(**params) | パラメータを設定 |
scikit-learn を用いた線形回帰の実行例: 準備
今回使用するデータ
今回は、UC バークレー大学の UCI Machine Leaning Repository にて公開されている、「Wine Quality Data Set (ワインの品質)」の赤ワインのデータセットを利用します。
データセットの各列は以下のようになっています。各行が 1 種類のワインを指し、1,599 件の評価結果データが格納されています。
| fixed acidity | 酒石酸濃度 |
|---|---|
| volatile acidity | 酢酸酸度 |
| citric acid | クエン酸濃度 |
| residual sugar | 残留糖濃度 |
| chlorides | 塩化物濃度 |
| free sulfur dioxide | 遊離亜硫酸濃度 |
| total sulfur dioxide | 亜硫酸濃度 |
| density | 密度 |
| pH | pH |
| sulphates | 硫酸塩濃度 |
| alcohol | アルコール度数 |
| quality | 0-10 の値で示される品質のスコア |
データセットは以下にて確認可能です。
データセットの読み込み
上記で説明したデータセット (winequality-red.csv) をダウンロードし、プログラムと同じフォルダに配置後、以下コードを実行し Pandas のデータフレームとして読み込みます。
import pandas as pd
import numpy as np
wine = pd.read_csv("winequality-red.csv", sep=";")
wine.head

scikit-learn を用いた線形回帰の実行例: 単回帰分析
まずは、1 つの説明変数を用いて単回帰分析を行います。
# sklearn.linear_model.LinearRegression クラスを読み込み from sklearn import linear_model clf = linear_model.LinearRegression() # 説明変数に "density (濃度)" を利用 X = wine.loc[:, ['density']].as_matrix() # 目的変数に "alcohol (アルコール度数)" を利用 Y = wine['alcohol'].as_matrix() # 予測モデルを作成 clf.fit(X, Y) # 回帰係数 print(clf.coef_) # 切片 (誤差) print(clf.intercept_) # 決定係数 print(clf.score(X, Y))
実行結果は以下のようになりました。
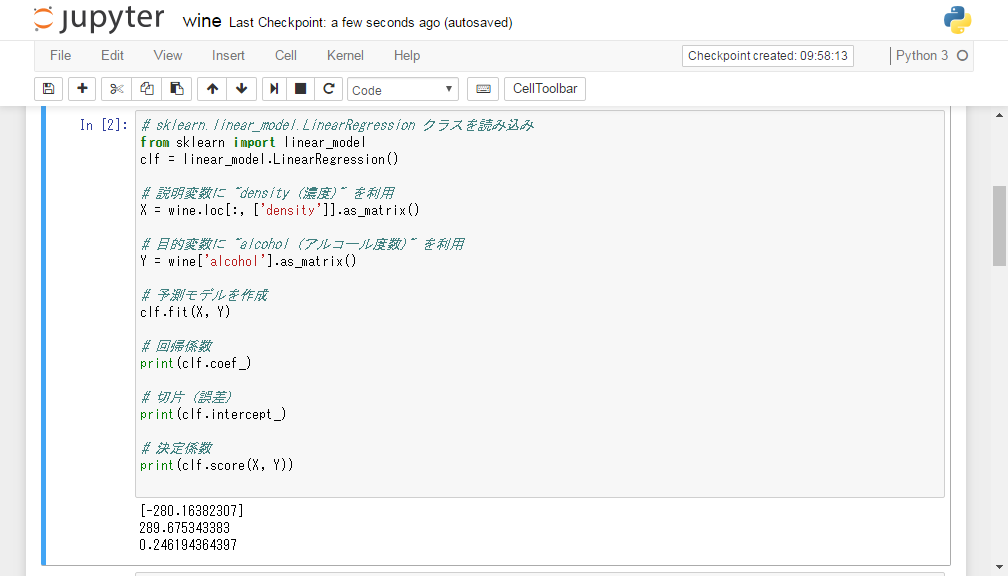
結果より、以下のように回帰式が求められたことがわかります。
[alcohol] = -280.16382307 × [density] + 289.675343383
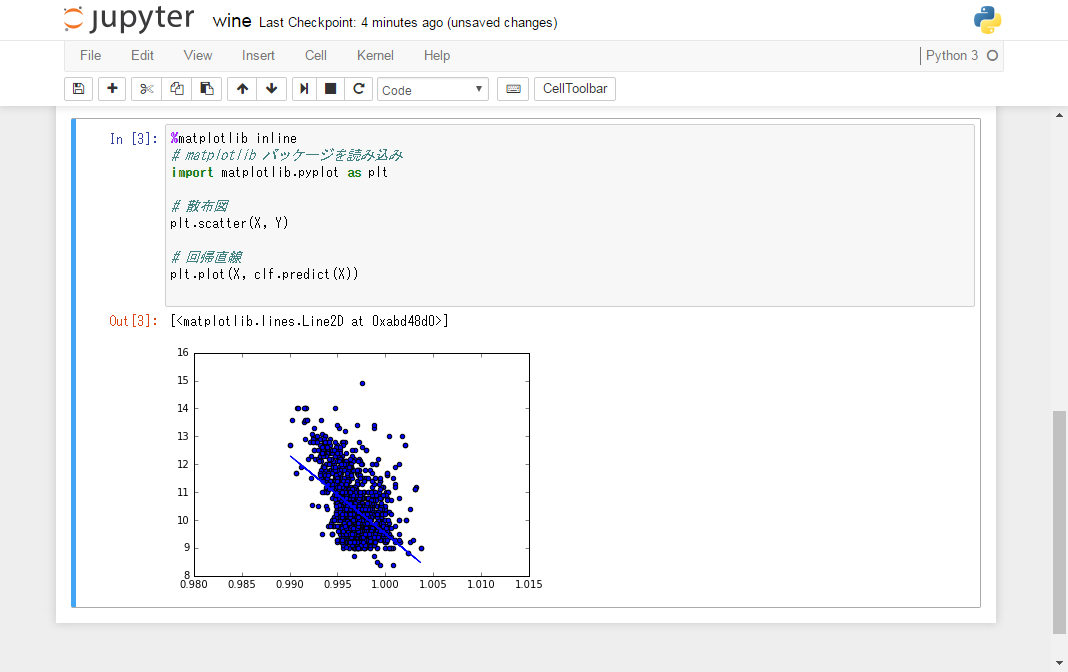
結果を 2 次元座標上にプロットすると、以下のようになります。青線が回帰直線を表します。
# matplotlib パッケージを読み込み import matplotlib.pyplot as plt # 散布図 plt.scatter(X, Y) # 回帰直線 plt.plot(X, clf.predict(X))
scikit-learn を用いた線形回帰の実行例: 重回帰分析
続いて、「quality」を目的変数に、「quality」以外を説明変数として、重回帰分析を行います。
from sklearn import linear_model
clf = linear_model.LinearRegression()
# 説明変数に "quality (品質スコア以外すべて)" を利用
wine_except_quality = wine.drop("quality", axis=1)
X = wine_except_quality.as_matrix()
# 目的変数に "quality (品質スコア)" を利用
Y = wine['quality'].as_matrix()
# 予測モデルを作成
clf.fit(X, Y)
# 偏回帰係数
print(pd.DataFrame({"Name":wine_except_quality.columns,
"Coefficients":clf.coef_}).sort_values(by='Coefficients') )
# 切片 (誤差)
print(clf.intercept_)
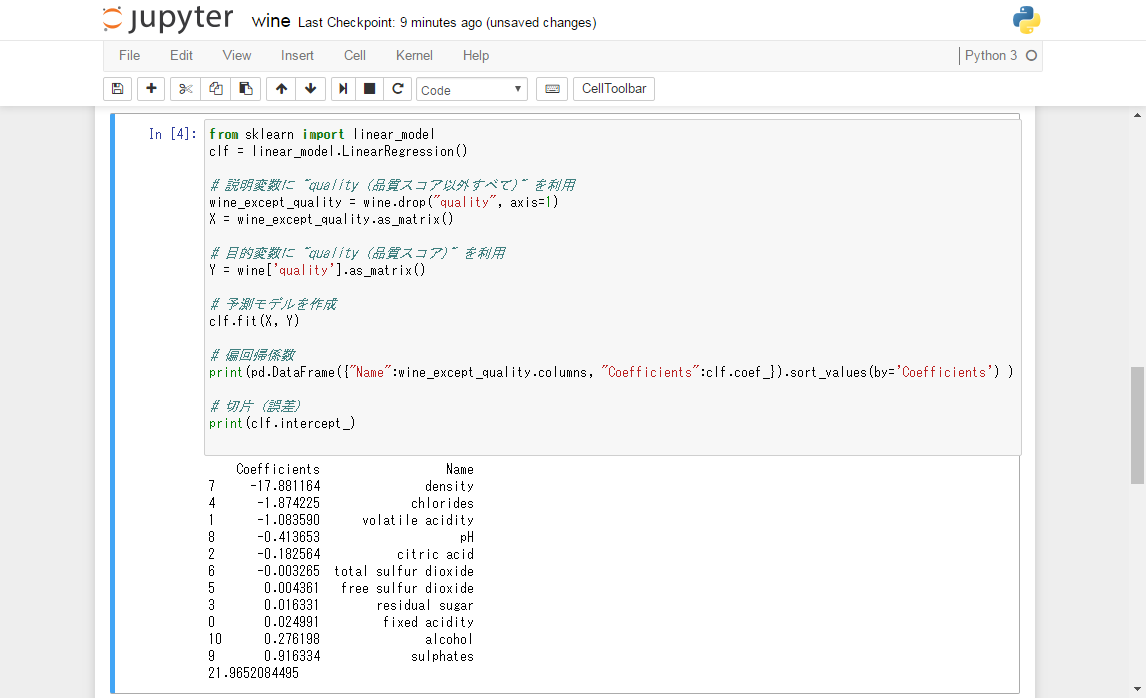
上記の結果からワインの品質スコアは、以下のような回帰式で表せることがわかります。
[quality] = -17.881164 × [density] + -1.874225 × [chlorides] +
-1.083590 × [volatile acidity] + -0.413653 × [pH] +
-0.182564 × [citric acid] + -0.003265 × [total sulfur dioxide] +
0.004361 × [free sulfur dioxide] + 0.016331 × [residual sugar] +
0.024991 × [fixed acidity] + 0.276198 × [alcohol] +
0.916334 × [sulphates] + 21.9652084495
scikit-learn を用いた線形回帰の実行例: 各変数を正規化して重回帰分析
各変数がどの程度目的変数に影響しているかを確認するには、各変数を正規化 (標準化) し、平均 = 0, 標準偏差 = 1 になるように変換した上で、重回帰分析を行うと偏回帰係数の大小で比較することができるようになります。
from sklearn import linear_model
clf = linear_model.LinearRegression()
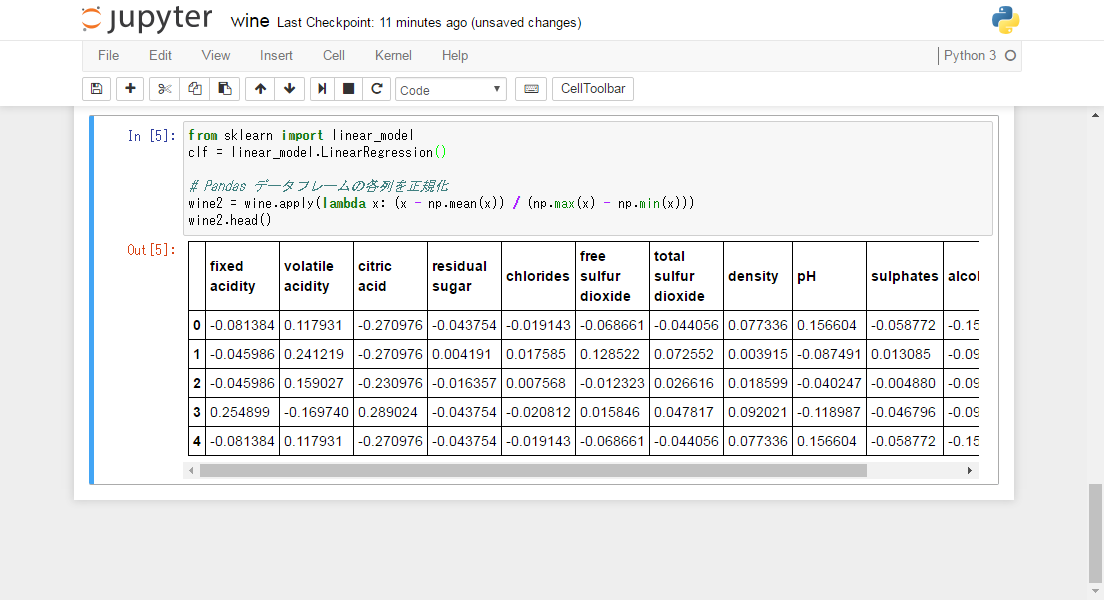
# データフレームの各列を正規化
wine2 = wine.apply(lambda x: (x - np.mean(x)) / (np.max(x) - np.min(x)))
wine2.head()
# 説明変数に "quality (品質スコア以外すべて)" を利用
wine2_except_quality = wine2.drop("quality", axis=1)
X = wine2_except_quality.as_matrix()
# 目的変数に "quality (品質スコア)" を利用
Y = wine2['quality'].as_matrix()
# 予測モデルを作成
clf.fit(X, Y)
# 偏回帰係数
print(pd.DataFrame({"Name":wine2_except_quality.columns,
"Coefficients":np.abs(clf.coef_)}).sort_values(by='Coefficients') )
# 切片 (誤差)
print(clf.intercept_)
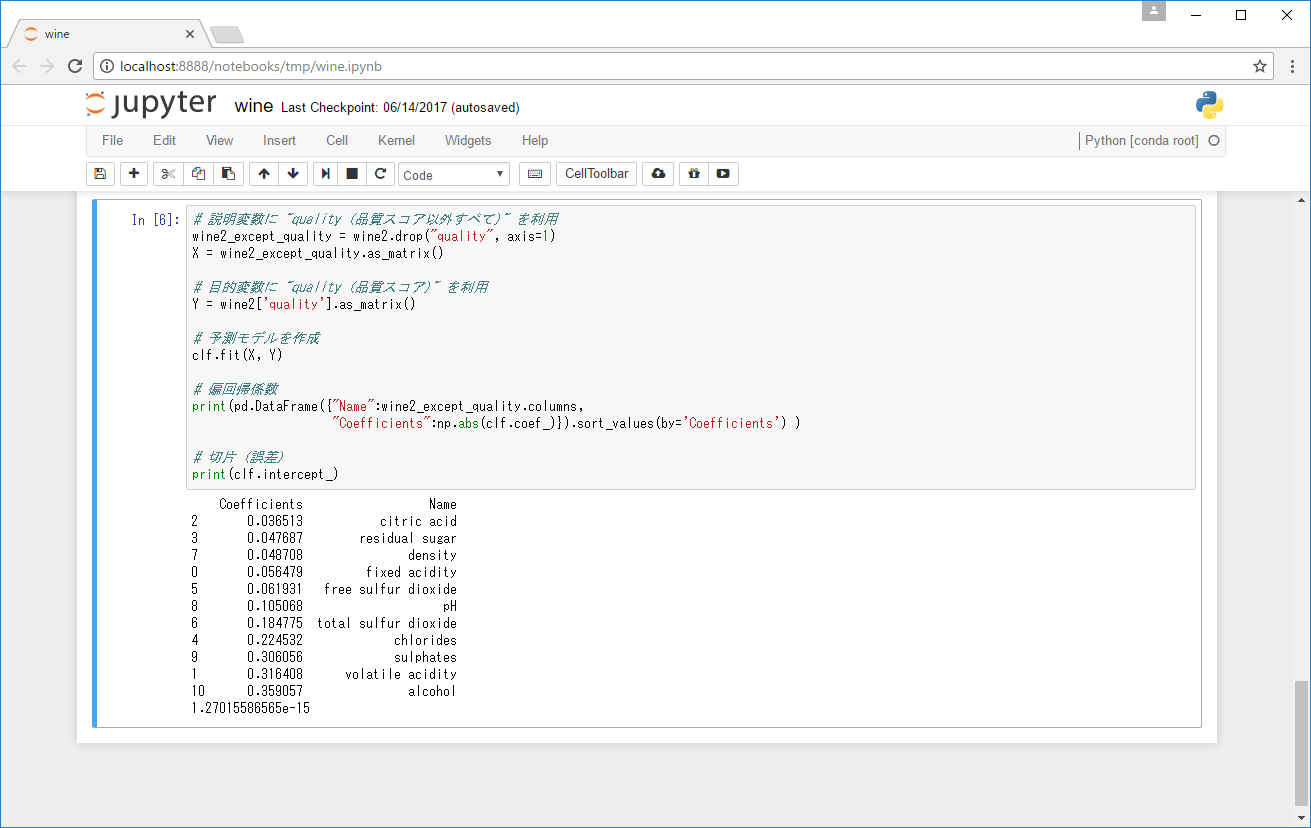
正規化した偏回帰係数を確認すると、alcohol (アルコール度数) が最も高い値を示し、品質に大きな影響を与えていることがわかります。
参考: 1.1. Generalized Linear Models — scikit-learn 0.17.1 documentation
sklearn.linear_model.LinearRegression — scikit-learn 0.17.1 documentation