本ページでは、Python の機械学習ライブラリの scikit-learn を用いてトレーニングデータとテストデータを作成するために、サンプリングを行なう手順を紹介します。
トレーニングデータ・テストデータとは
教師あり機械学習(回帰分析、決定木分析、ランダムフォレスト法、ナイーブベイズ法、ニューラルネットワークなど)によるモデルを作成するには、準備したデータセットをトレーニングデータ(訓練用データ、学習用データとも呼ばれます)とテストデータ(検証用データ、評価用データ、検証用データとも呼ばれます)の 2 つに分割して予測モデルの作成、評価を行なうことが一般的です。このように一定の割合でトレーニングデータとテストデータに分割することをホールドアウト (hold-out) と呼びます。
以下は、クレジットカードの解約予測の分析テーマを例に挙げて、そのイメージを説明します。
トレーニングデータとテストデータの分割
データセット全体 (20 レコード) を本例では、80 : 20 の割合でトレーニングデータ (16 件) とテストデータ (4件) に分割します。
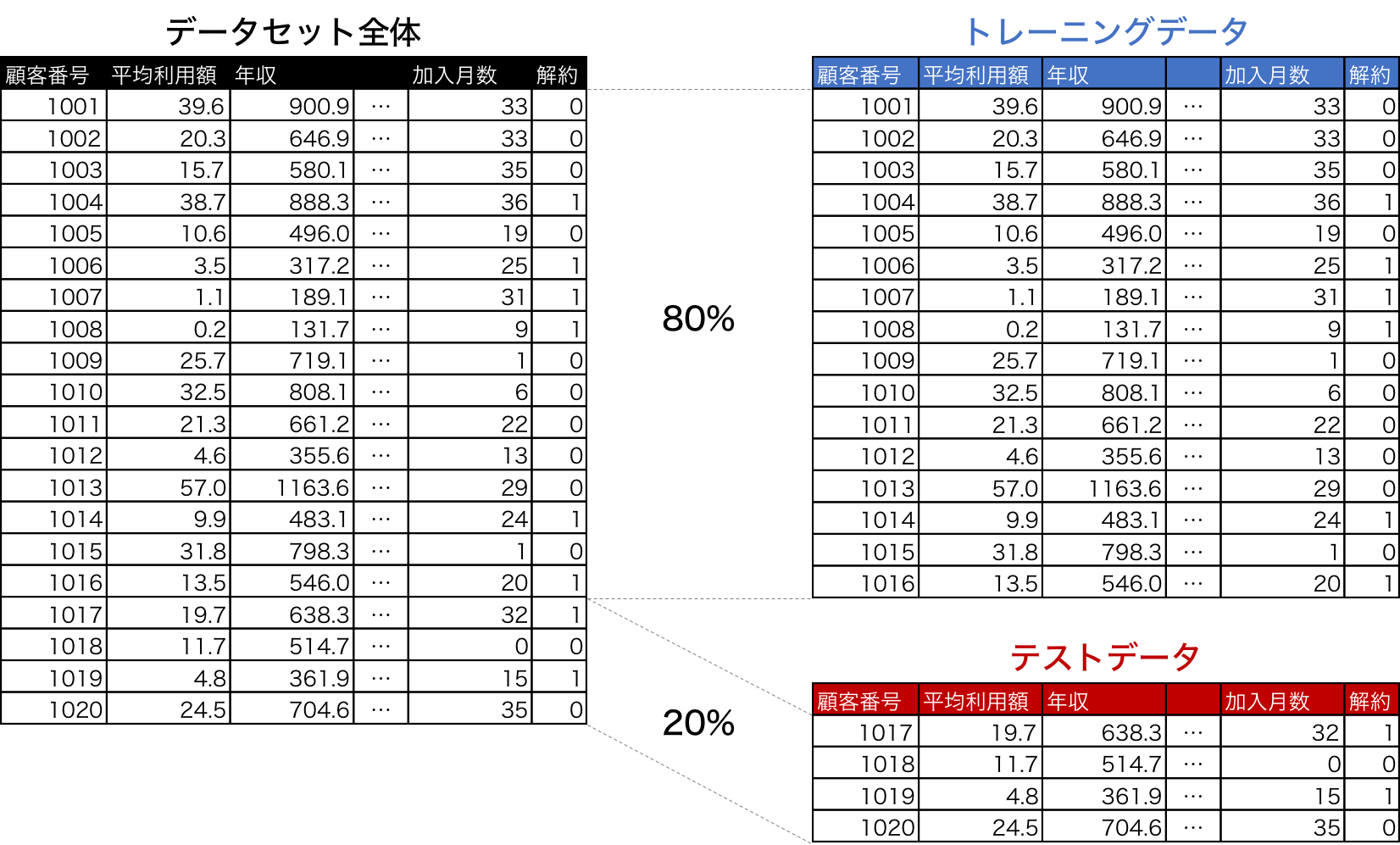
トレーニングデータとテストデータはどのような割合 (何対何) で分割すべきといった決まりはありませんが、トレーニングデータ : テストデータを 80 % : 20 % や、75 % : 25 % 、70 % : 30 % の比率で分割することが一般的です。
トレーニングデータを用いた機械学習モデルの作成
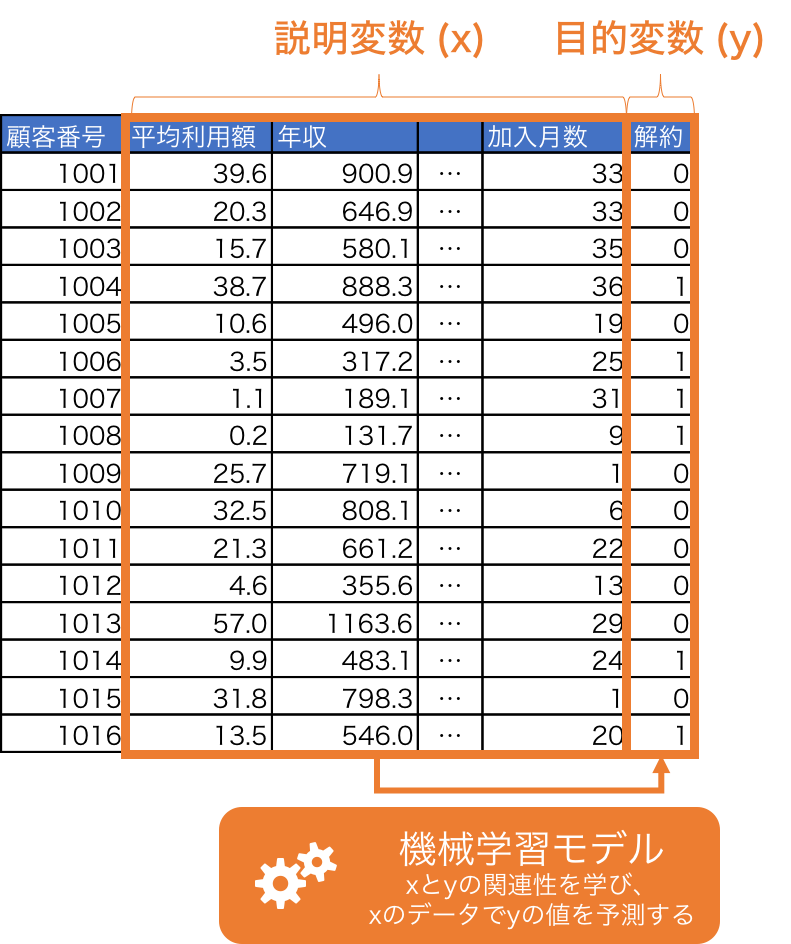
分割したデータのうち、トレーニングデータのみを用いて、説明変数 (x) と目的変数 (y) の関係性を学習し、説明変数 (x) が与えられたときに、目的変数 (y) を返す機械学習モデルを作成します。
テストデータを用いた予測の実行
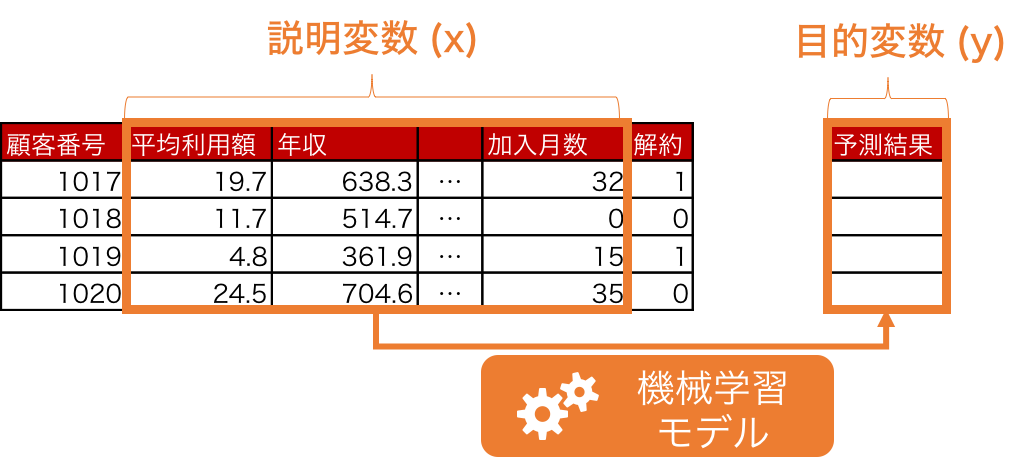
続いて、作成した機械学習モデルとテストデータの説明変数 (x) のみを用いて、予測結果を算出します。
テストデータを用いた評価
前段で求めた予測結果と、実際の解約有無を比較することで、どれだけ正確に予測できるかを確認することで、機械学習モデルの予測性能を測ります。

サンプリングを行なうときに注意すべきこと
データセット全体からレーニングデータとテストデータを分割する際に、データの特性に偏りのあるトレーニングデータやテストデータを使って機械学習モデルを作成すると、精度の悪いモデルができてしまいます。それを防ぐために、ランダムに並び替えたデータからデータセットを抽出します。そのような作業をサンプリング、特に、ランダムに抽出することをランダムサンプリングと呼びます。
train_test_split: トレーニングデータとテストデータを分割
scikit-learn には、トレーニングデータとテストデータの分割を行なうメソッドとしてsklearn.model_selection.train_test_split が用意されています。このメソッドは、与えられたデータフレームから、指定された条件に基づいてトレーニングデータとテストデータを分割します。
train_test_split の使い方
sklearn.model_selection.train_test_split(*arrays, **options)
train_test_split の引数
| arrays | 分割対象の同じ長さを持った複数のリスト、Numpy の array, matrix, Pandasのデータフレームを指定。 |
|---|---|
| test_size | 小数もしくは整数を指定。小数で指定した場合、テストデータの割合を 0.0 〜 1.0 の間で指定します。整数を指定した場合は、テストデータに必ず含めるレコード件数を整数で指定します。指定しなかった場合や None を設定した場合は、train_size のサイズを補うように設定します。train_size を設定していない場合、デフォルト値として 0.25 を用います。 |
| train_size | 小数もしくは整数を指定。小数で指定した場合、トレーニングデータの割合を 0.0 〜 1.0 の間で指定します。整数を指定した場合は、トレーニングデータに必ず含めるレコード件数を整数で指定します。指定しなかった場合や None を設定した場合は、データセット全体から test_size を引いた分のサイズとします。 |
| random_state | 乱数生成のシードとなる整数または、RandomState インスタンスを設定します。指定しなかった場合は、Numpy のnp.random を用いて乱数をセットします。 |
| shuffle | データを分割する前にランダムに並び替えを行なうかどうか。True または False で指定します。False に設定した場合、stratify を None に設定しなければいけません。(デフォルト値: True) |
| stratify | Stratified Sampling (層化サンプリング) を行なう場合に、クラスを示す行列を設定します。 (デフォルト値: None) |
train_test_split の使用例
今回使用するデータフレーム (4 カラム、12 レコード) を作成します
>>> import pandas as pd
>>> from sklearn.model_selection import train_test_split
>>>
>>> namelist = pd.DataFrame({
... "name" : ["Suzuki", "Tanaka", "Yamada", "Watanabe", "Yamamoto",
... "Okada", "Ueda", "Inoue", "Hayashi", "Sato",
... "Hirayama", "Shimada"],
... "age": [30, 40, 55, 29, 41, 28, 42, 24, 33, 39, 49, 53],
... "department": ["HR", "Legal", "IT", "HR", "HR", "IT",
... "Legal", "Legal", "IT", "HR", "Legal", "Legal"],
... "attendance": [1, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 1]
... })
>>> print(namelist)
age attendance department name
0 30 1 HR Suzuki
1 40 1 Legal Tanaka
2 55 1 IT Yamada
3 29 0 HR Watanabe
4 41 1 HR Yamamoto
5 28 1 IT Okada
6 42 1 Legal Ueda
7 24 0 Legal Inoue
8 33 0 IT Hayashi
9 39 1 HR Sato
10 49 1 Legal Hirayama
11 53 1 Legal Shimada
テストデータを 30% (test_size=0.3) としてトレーニングデータ、テストデータに分割します。
>>> namelist_train, namelist_test = train_test_split(namelist, test_size=0.3)
>>> print(namelist_train)
age attendance department name
10 49 1 Legal Hirayama
1 40 1 Legal Tanaka
7 24 0 Legal Inoue
2 55 1 IT Yamada
4 41 1 HR Yamamoto
3 29 0 HR Watanabe
9 39 1 HR Sato
6 42 1 Legal Ueda
>>> print(namelist_test)
age attendance department name
0 30 1 HR Suzuki
8 33 0 IT Hayashi
11 53 1 Legal Shimada
5 28 1 IT Okada
テストデータを具体的な数値で、5 件 (test_size=5) としてトレーニングデータ、テストデータに分割します。
>>> namelist_train, namelist_test = train_test_split(namelist, test_size=5)
>>> print(namelist_train)
age attendance department name
3 29 0 HR Watanabe
4 41 1 HR Yamamoto
6 42 1 Legal Ueda
1 40 1 Legal Tanaka
9 39 1 HR Sato
8 33 0 IT Hayashi
7 24 0 Legal Inoue
>>> print(namelist_test)
age attendance department name
2 55 1 IT Yamada
10 49 1 Legal Hirayama
5 28 1 IT Okada
11 53 1 Legal Shimada
0 30 1 HR Suzuki
トレーニングデータを 50% (training_size=0.5) としてトレーニングデータ、テストデータに分割します。
>>> namelist_train, namelist_test = train_test_split(namelist, test_size=None, train_size=0.5)
>>> print(namelist_train)
age attendance department name
5 28 1 IT Okada
2 55 1 IT Yamada
3 29 0 HR Watanabe
4 41 1 HR Yamamoto
10 49 1 Legal Hirayama
0 30 1 HR Suzuki
>>> print(namelist_test)
age attendance department name
6 42 1 Legal Ueda
7 24 0 Legal Inoue
9 39 1 HR Sato
11 53 1 Legal Shimada
8 33 0 IT Hayashi
1 40 1 Legal Tanaka
データの並び替え(シャッフル)を行わないで、分割のみを実施します。
>>> namelist_train, namelist_test = train_test_split(namelist, shuffle=False)
>>> print(namelist_train)
age attendance department name
0 30 1 HR Suzuki
1 40 1 Legal Tanaka
2 55 1 IT Yamada
3 29 0 HR Watanabe
4 41 1 HR Yamamoto
5 28 1 IT Okada
6 42 1 Legal Ueda
7 24 0 Legal Inoue
8 33 0 IT Hayashi
>>> print(namelist_test)
age attendance department name
9 39 1 HR Sato
10 49 1 Legal Hirayama
11 53 1 Legal Shimada
乱数のシードを 42 に固定します。1 回目と 2 回目で全く同じサンプリングがなされていることが見て取れます。
>>> namelist_train, namelist_test = train_test_split(namelist, random_state=42)
>>> print(namelist_train)
age attendance department name
8 33 0 IT Hayashi
5 28 1 IT Okada
2 55 1 IT Yamada
1 40 1 Legal Tanaka
11 53 1 Legal Shimada
4 41 1 HR Yamamoto
7 24 0 Legal Inoue
3 29 0 HR Watanabe
6 42 1 Legal Ueda
>>> print(namelist_test)
age attendance department name
10 49 1 Legal Hirayama
9 39 1 HR Sato
0 30 1 HR Suzuki
>>> namelist_train, namelist_test = train_test_split(namelist, random_state=42)
>>> print(namelist_train)
age attendance department name
8 33 0 IT Hayashi
5 28 1 IT Okada
2 55 1 IT Yamada
1 40 1 Legal Tanaka
11 53 1 Legal Shimada
4 41 1 HR Yamamoto
7 24 0 Legal Inoue
3 29 0 HR Watanabe
6 42 1 Legal Ueda
>>> print(namelist_test)
age attendance department name
10 49 1 Legal Hirayama
9 39 1 HR Sato
0 30 1 HR Suzuki
“department” のクラスによる層化サンプリングを行います。
層化サンプリングとは、サンプリングしたデータが偏らないよう、指定した変数の出現頻度が一定になるように調整した上で、サンプリングを行なうものです。以下の例では、”department” (=部門) を stratify=namelist['department'] として指定しているので、テストデータには、各部門 (IT (情報システム), HR (人事), Legal (法務)) が、全体の分布と同じになるよう、各 1 件ずつ抽出されています。
>>> namelist_train, namelist_test = train_test_split(namelist, stratify=namelist['department'])
>>> print(namelist_train)
age attendance department name
8 33 0 IT Hayashi
7 24 0 Legal Inoue
5 28 1 IT Okada
10 49 1 Legal Hirayama
0 30 1 HR Suzuki
4 41 1 HR Yamamoto
1 40 1 Legal Tanaka
9 39 1 HR Sato
11 53 1 Legal Shimada
>>> print(namelist_test)
age attendance department name
2 55 1 IT Yamada
6 42 1 Legal Ueda
3 29 0 HR Watanabe
上記で説明した層化サンプリングを “attendance” (総会への出席状況) の列に基づいて実施した例は以下になります。テストデータには、1 が 2 件、0 が 1 件と、全体の分布とほぼ同じように抽出されていることがわかります。
>>> namelist_train, namelist_test = train_test_split(namelist, stratify=namelist['attendance'])
>>> print(namelist_train)
age attendance department name
7 24 0 Legal Inoue
8 33 0 IT Hayashi
2 55 1 IT Yamada
11 53 1 Legal Shimada
10 49 1 Legal Hirayama
0 30 1 HR Suzuki
6 42 1 Legal Ueda
1 40 1 Legal Tanaka
9 39 1 HR Sato
>>> print(namelist_test)
age attendance department name
5 28 1 IT Okada
3 29 0 HR Watanabe
4 41 1 HR Yamamoto
例えば、説明変数 x (attendance 以外) と 目的変数 y (attendance) を分割し、train_test_split に 2 つ以上の引数を与えることもできます。以下の例では、データフレームとarray を渡し、データフレーム、array を 2 つずつ返します。
>>> # データセットを説明変数と目的変数に分割
>>> namelist2_x = namelist.drop("attendance", axis=1)
>>> namelist2_y = namelist['attendance']
>>> # 説明変数
>>> print(namelist2_x)
age department name
0 30 HR Suzuki
1 40 Legal Tanaka
2 55 IT Yamada
3 29 HR Watanabe
4 41 HR Yamamoto
5 28 IT Okada
6 42 Legal Ueda
7 24 Legal Inoue
8 33 IT Hayashi
9 39 HR Sato
10 49 Legal Hirayama
11 53 Legal Shimada
>>> # 目的変数
>>> print(namelist2_y)
0 1
1 1
2 1
3 0
4 1
5 1
6 1
7 0
8 0
9 1
10 1
11 1
Name: attendance, dtype: int64
サンプリングを実施し、トレーニングデータ、テストデータに分割します。
>>> x_train, x_test, y_train, y_test = train_test_split(namelist2_x, namelist2_y, test_size=0.3)
>>> # 説明変数 (トレーニングデータ)
>>> print(x_train)
age department name
0 30 HR Suzuki
10 49 Legal Hirayama
2 55 IT Yamada
5 28 IT Okada
4 41 HR Yamamoto
8 33 IT Hayashi
6 42 Legal Ueda
11 53 Legal Shimada
>>> # 説明変数 (テストデータ)
>>> print(x_test)
age department name
9 39 HR Sato
7 24 Legal Inoue
1 40 Legal Tanaka
3 29 HR Watanabe
>>> # 目的変数 (トレーニングデータ)
>>> print(y_train)
0 1
10 1
2 1
5 1
4 1
8 0
6 1
11 1
Name: attendance, dtype: int64
>>> # 目的変数 (テストデータ)
>>> print(y_test)
9 1
7 0
1 1
3 0
Name: attendance, dtype: int64
参考:
sklearn.model_selection.train_test_split — scikit-learn 0.19.0 documentation